Release of Stable Diffusion 2.0 by Stability AI

Users have the ability to generate anything from text in 2022 because it was the year of generative AI. The open-source release of Stable Diffusion 2.0 was announced by Stability AI, and the year isn’t even halfway through yet. With its text-to-image model known as “eDiffi” or “ensemble diffusion for images,” NVIDIA just entered the generative industry to compete with Google’s Imagen, Meta’s “Make a Scene,” and other solutions.
The New Stable Diffusion 2.0
In comparison to the initial V1 release, Stable Diffusion 2.0 offers better features and improvements. A new encoder called OpenCLIP, created by LAION with assistance from Stability AI, is used to train robust text-to-image models in the new release, which enhances the quality of the images that are produced. The models included in the release are capable of producing images with 512×512 and 768×768 pixel default resolutions.
The DeepFloyd team’s LAION-5b dataset subset is used to train the models. These are then used to further filter adult content using the dataset’s NSFW filter.
 Input image used to produce several new images
Input image used to produce several new imagesIn comparison to the open-source text-to-image DALL.E 2 and Stable Diffusion, eDiffi delivers an unprecedented text-to-image synthesis with intuitive painting. Along with that, it also offers word capabilities, and fast style transfer, producing outcomes with higher synthesis quality.
Upscaler Diffusion Models
The 2.0 version also includes an Upscaler Diffusion model. It increases image resolution or quality by a factor of 4 in addition to the generative model. As an illustration, the image below shows an image that has been upscaled from a low-resolution generated image (128×128) to a higher resolution (512×512).
The company claimed that Stable Diffusion 2.0 will be able to produce images with resolutions of 2048×2048. It could also be even higher by fusing this model with their text-to-image models.
 Stability AI Releases Stability Diffusion 2.0
Stability AI Releases Stability Diffusion 2.0Additionally, for innovative implementations of the model, the depth-to-image model (depth2img) extends all previous capabilities of the image-to-image option from the V1.
This feature would generate new images utilizing text and depth information. It would do so by inferring the depth of an input image with the aid of the current model.
How does this change AI
Innovators all across the world have been inspired by the initial CompVis-led Stable Diffusion V1. It transformed the way open-source AI generative models were created. The V1 climbed to 10,000 GitHub stars among the fastest of any software, racking up 33K ratings in less than two months.
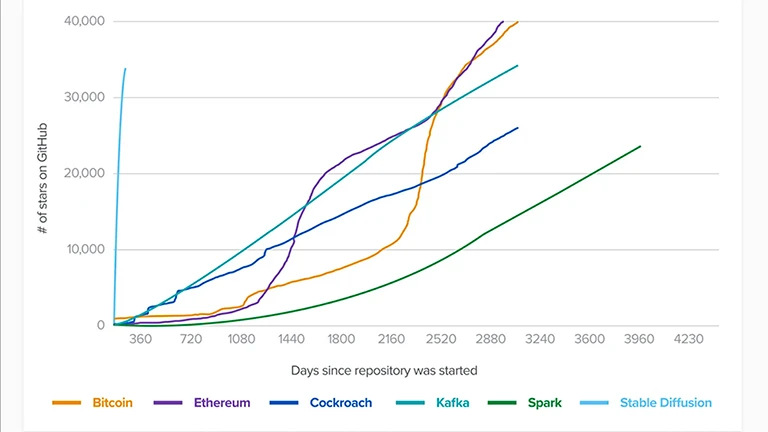 Stable Diffusion Developer Adoption
Source: A16z and Github
Stable Diffusion Developer Adoption
Source: A16z and GithubThe dynamic collaboration of Robin Rombach from Stability AI, Patrick Esser from Runway ML, and Professor Dr. Björn Ommer from the CompVis Group at LMU Munich oversaw the initial Stable Diffusion V1 release. The older version had assistance from Eleuther AI and LAION. It was based on their earlier work as well as Latent Diffusion Models. According to the site, Rombach is currently directing developments with Katherine Crowson to develop the following generation of media models.









